My experiments with prompt programming and generating AI images using non-English & non-Latin languages prompts (very long)

AI-generated image from Dall-e mini, 2022 😤️
prompt: Sô-cô-la nóng với lớp kem ở trên (Vietnamese for hot chocolate with cream on top)
Anything I write that might be wrong, please do correct me but be polite about it, thank you!
PS: I intend to continue experimenting here and will update as I go.
PPS: I just realised that my prompts might suck too, to be fair I haven’t followed all the suggestions I wrote up on my other article about prompt programming, so will update as I experiment
Date: Friday 24/06/22
At my day job with Child Rights International Network, I had to design and typeset a series of 43 reports / publications on Children’s Access to Environmental Justice, which were translated from English to the language of the specific country the report was based in. One of the translations was the Thailand report, which was obviously in Thai. Although we had a translator working alongside us, I had a gut feeling that this was going to be a difficult process.
One of the biggest issues we encountered was that InDesign wasn’t working well with hyphenation for Thai glyphs (I had Adobe World Composer on and hyphenation disabled) and since Thai as a language has a completely different usage of the ‘space’, it was really hard to determine the difference between a line break and a word that is broken in half . In short, we ended up with a document that was filled with mistakes, the whole thing was illegible. I asked a Thai designer friend of mine who said their friends simply manually sort out the line breaks.
This process made me realise how limited some softwares and websites are to non-Latin languages. So when I started playing DALL-E mini and MindsEye beta, I had questions, lots and lots of questions. Now the first disclaimer here is that I am not 100% sure where the engineers behind both art generators find their data, but after watching Vox’s great video on AI art, it pointed out that some of the data is based on image descriptions, such as the ones you would find on wikipedia as ‘captions’ or even the alt-image descriptions you would have for accessibility reasons. I also read a great article where Brazilian screenwriter Fernando Marés tried to generate art based on empty prompts, and realised that blank prompts generated women in saris, what the hell lol! DALL·E mini was developed by AI artist Boris Dayma who was confused by this result, and guesses that “It’s also possible that this type of image was highly represented in the dataset, maybe also with short captions,”
From there I wondered that since over 62% of the content on the Internet is written in English, and DALL-E mini is designed by engineers who have used English as their main form of communication, does this mean that English prompts will work better than other languages such as French or Spanish prompts? What about languages with roots which are very different to English such as Vietnamese or Lithuanian? What about non-Latin languages like Thai or Arabic? So I did some tests on both DALL-E Mini and MindsEye Beta.
For MindsEye, I used the model: CLIP Guided Diffusion. It is described as “Coherent and Structured, it can compose images with high quality results. The selected implementation is Disco Diffusion v5”
Bias disclaimer: Before I continue, I want to copy-paste DALL-E mini’s bias disclaimer which is relevant to this whole experiment: While the capabilities of image generation models are impressive, they may also reinforce or exacerbate societal biases. While the extent and nature of the biases of the DALL·E mini model have yet to be fully documented, given the fact that the model was trained on unfiltered data from the Internet, it may generate images that contain stereotypes against minority groups. Work to analyze the nature and extent of these limitations is ongoing, and will be documented in more detail in the DALL·E mini model card.
Also these AI generators are not as clean as DALL-E 2, so their messiness is expected.
Also as I did each experiment, I also did an English version of each prompt just to check, and everytime it gave the exact result of said object I just didn’t post them here to avoid clutter. If there are any English prompts that don’t work either, I will mention it of course!
1. Experiments with French
As a French native speaker, I started with a basic word which was ‘un croissant enfourné’ which OBVIOUSLY gave me an AI generated croissant.
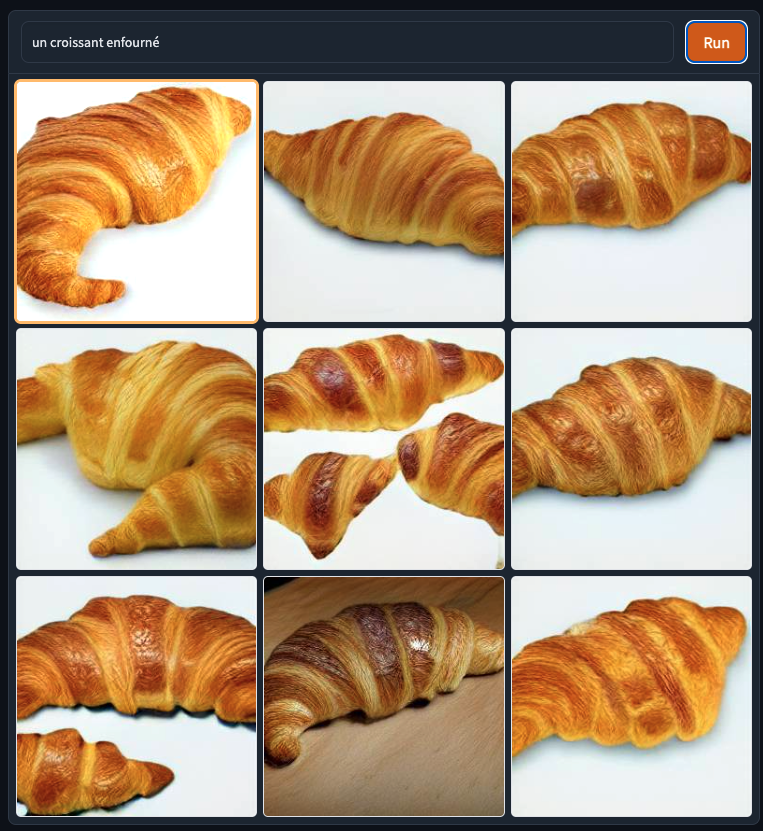
(1 try) DALL-E mini: ✅ Yes, I expected it to be in an oven but the croissant is there!

(1 try) MindsEye: ✅ Croissant could be fresher, but deffo a croissant
I realised it was not a good prompt representation as croissant is a transparent word. So I went for a non-transparent word: un petit garçon (a little boy)
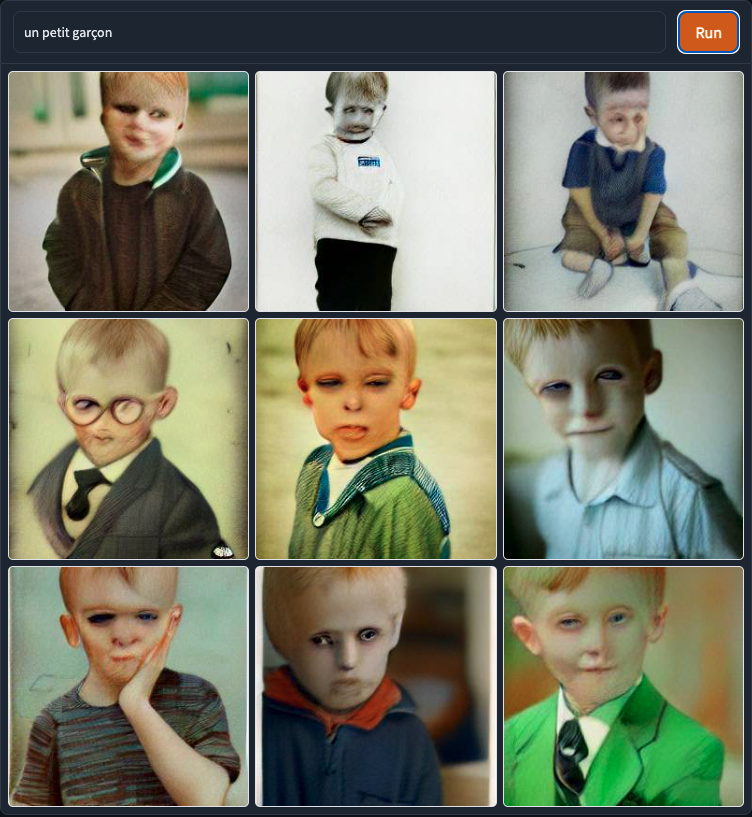
(1 try) DALL-E mini: ✅ And it totally gave me a little boy!

(3 tries) MindsEye: ✅ Yes-ish. It’s deffo a little boy but he ain’t looking too fresh. First two times didn’t work and gave me disturbing results. I’m not sure what was in there, a rat? a frog? both? on a roll of intestine?
Ok, let’s push it more. Garçon is not a complex word, and isn’t transparent but is a very common French word. So I wrote a more complex prompt: ‘Un petit garçon qui porte de grosses bottes rayées et qui tient une poupée’ (a little boy wearing big striped boots, holding a doll)

(1 try) DALL-E mini: ✅ Totally worked, though he is wearing the stripes on his shirt but STILL

(1 try) MindsEye: ✅ Yes-ish, it was a bit messy but had the general idea, the boot and the boy are both there, no stripes though
Great! Let’s do another test. This time, I tried objects as opposed to humans, as humans are never clear on those AI generators compared to actual things.
I went for ‘Un grand frigo rempli de victuailles’ (a big fridge full of food).

(1 try) DALL-E mini: ✅ Yes-ish BUT interestingly it didn’t pick up on the word ‘victuailles’ so the fridge was empty loooool

(1 try) MindsEye: ✅ Yes-ish BUT the fridge is filled of a mix of drinks and pots and pans and drawers ahaha, also why the hell is it outside?
Since DALL-E mini didn’t pick up on the word ‘victuailles’ and MindsEye struggled too, I assumed it was because the word was too ‘old school’ as the word is quite ancient and formal lol (I picked this word because i was reading a Le Petit Nicolas story).
So I replaced it with ‘nourriture’ which is the normal word for food! And....

(1 try) DALL-E mini: ✅ Yes totally worked perfectly

(1 try) MindsEye: ✅ Yes-ish, it’s actual food, but it did start as a microwave and slowly became a horizontal fridge ahaha, only food in the freezer but it’s a start! Again, why is it outside??
French Summary: Great! So French works fairly ok! It doesn’t pick up on old, rarer terms like ‘victuailles’, but it got the majority of prompts.
2. Vietnamese experiment
Since Vietnamese is a Latin-based language but with very different roots (some Portuguese missionary called Francisco de Pina transcribed the Viet language which was originally in Chinese characters into Latin but based on Portuguese orthography) and then the French got all colonially and enforced the Latin version of the Viet alphabet and I guess we got some French-inspired words in there too, like ‘phô mai’ for ‘cheese’ from ‘fromage’ and ‘sô-cô-la‘ for ‘chocolate’ from ‘chocolat’ as you are about to see now!!!
So for the first test, the prompt was ‘Sô-cô-la nóng với lớp kem ở trên’, which is
‘Hot chocolate with cream on top‘ in English.
(2 tries) DALL-E mini: 🚫️ LMFAO Bro why is it so sexual for real lol I did two tries just in case too.

(1 try) MindsEye: 🚫️ HM super fleshy outcome, wouldn’t you say lool 🧐️
So at this point I can only assume three things:
- either it picked up on the existing bias / stereotypical association of Asian women and sex / hentai / pornography on the web,
- and/or the majority of images / image descriptions of Vietnamese-based content on the Internet is related to pornography,
- and/or it mainly picked up on the words ‘hot’ and ‘cream’ which... really didn’t help lmao
Let’s try again! This time I gave it a very neutral prompt, no ‘hot’ or ‘sexy’ words.
I went for ‘một bức ảnh của một quả táo’ which means ‘a photo of an apple‘
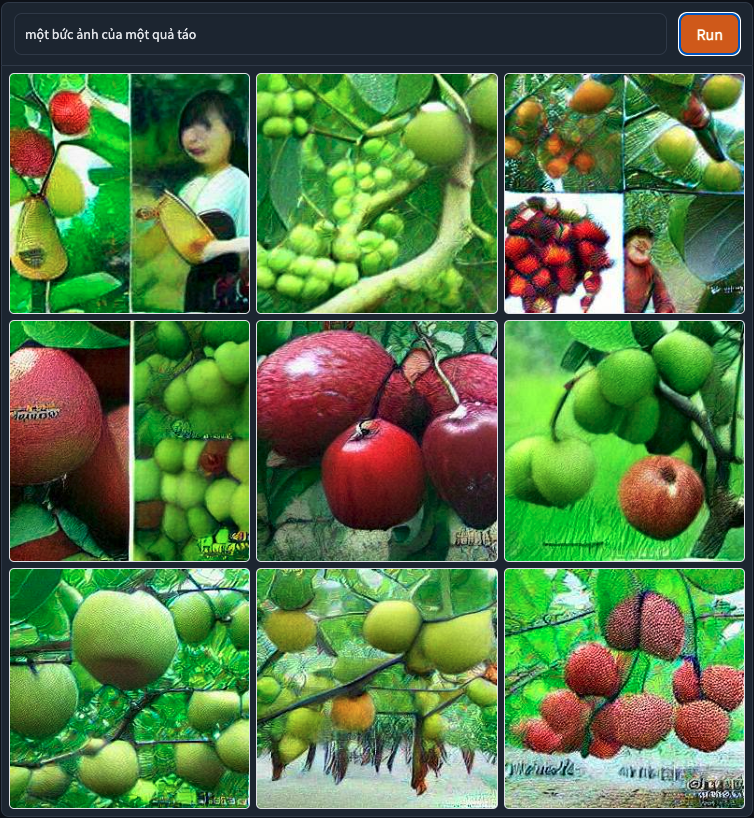
(1 try) DALL-E mini: ✅ Yes totally worked perfectly

(1 try) MindsEye: 🚫️ HAHAHA NO it gave me a random image of a Viet-ish looking boy!
OK let’s try again. This time I went for ‘bóng bàn‘ which literally means ping-pong ahhaa

(2 tries) DALL-E mini: 🚫️ Nah gave me some random viet bois again, twice

(2 tries) MindsEye: 🚫️ Ok so both tries failed, but this one was WEIRD! Both results started off as a monstruous looking ‘Bing Bong’ from Inside Out (Pixar film), and since the prompt was ‘bóng bàn‘ I guess I wasn’t surprised!
Viet Summary: Similar to the Hindi and Arabic tests, it sometimes picks up on the language of the prompts being Vietnamese and associate it often with actual Viet-looking humans or to the closest English term / popular Internet term (so ‘bóng bàn‘ = Bing Bong from Inside Out)
3. Hindi experiment
PS: For the translations, I went on Wikipedia first as articles are already vetted and approved in terms of legibility and then clicked on the Masala Chai article written in Hindi and copy pasted the title straight away to ensure it was correct. For the second prompt, I also went on Google Translate to find the words ‘a picture of’. Let me know if it’s mistranslated.
For the first prompt, I went for a simple one, I just had to complete an illustration commission for a South Asian Film Hub event and wrote some Hindi (masala chai). So I took ‘Masala chai’ in Hindi: मसाला चाय

(2 tries) DALL-E mini: 🚫️ Nah each time it gave me Indian people with bindis

(2 tries) MindsEye: 🚫️ Again with the random South Asian-looking person with a bindi! First time it gave me a random landscape with Hindi written all over it, this time a person with a bindi and a lit cigarette in their mouth!
Ok let’s try again, this time we’re gonna go for a more detailed prompt: मसाला चाय की एक तस्वीर which is Hindi for ‘A picture of masala tea’

(2 tries) DALL-E mini: 🚫️ Aha did two tries and again, gave me random South Asian-looking people in crowds and gatherings, mostly men aswell, and some are wearing saris or white shirts and white trousers. They all seem to be photos taken outside too.

(3 tries) MindsEye: 🚫️ At first it gave me an ok-ish result with something looking vaguely like a puddle of golden tea. Then it just gave me more random landscapes with vague Hindi written on them.
Hindi Summary: Similar to the Viet, Thai and Arabic tests, it sometimes picks up on the language of the prompts being Hindi and associate it often with actual humans who look Indian or who wears bindis, or even random environments with abstract, Hindi-looking glyphs printed.
4. Thai experiment
The first prompt was the same as before, which is Masala chai again! I simply changed the Wikipedia language to Thai and copy pasted it again. Interestingly, when I did a check with Google Translate on the Wiki page, I noticed that Masala chai was translated as ‘Malajai’!
Prompt: มาลาจาอิ or ‘Malajai / Masala chai’ in English

(2 tries) DALL-E mini: 🚫️ Ok so my own biases are coming into play in this ‘guess the rorschach’, but I’m assuming these are landscapes that can be found in Thailand? I might recognise the top left image, as a Vietnamese buddhist, it looks a lot like the images of buddhas (either drawn or statues).

(3 tries) MindsEye: 🚫️ At first it gave me a close-up of a giant Asian baby ahahhaa with some what I think is Thai-looking glyphs scribbled on its forehead, but then the next two tries always gave me a weird mouse / anime / asian boy hybrid
Then i did a translation on Google Translate to add ‘a picture of’, so the second prompt is:
ภาพของมาลาจาอิ ‘a picture of malajai’

(1 try) DALL-E mini: 🚫️ Nope, generated a series of Asian-looking people wearing a mix of sarongs and suits, with a temple at the top left!

(2 tries) MindsEye: 🚫️ No, each time a similar result, it printed what looks like a human / monkey hybrid, with a lot of fur and what looks like a pink lotus flower on the nose and some Thai-looking glyphs on the forehead!
Thai Summary: Similar to the Viet, Arabic and Hindi tests, it sometimes picks up on the language of the prompts being Thai and associate it often with actual humans who look Asian or who wears clothing found in the culture such as the sarongs or other cultural references such as the image that reminded me of buddhist art / sculptures, and landscapes / environments with abstract, Thai-looking glyphs printed.
5. Arabic experiment
For the first prompt, I went back in Wikipedia and chose a simple, humble doughnut, which in Arabic is: دونات
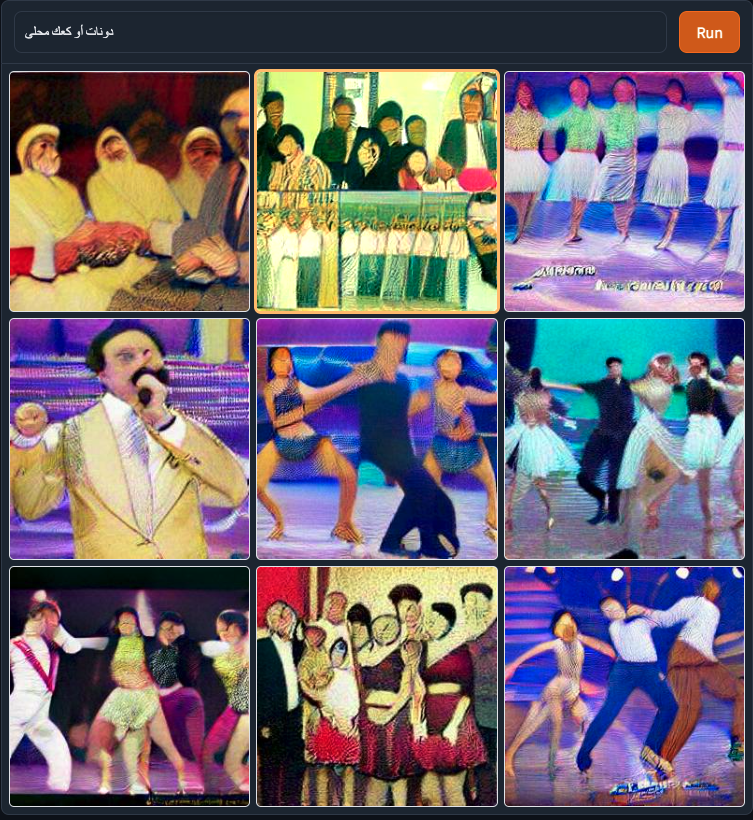
(1 try) DALL-E mini: 🚫️ Haha it gave me lots of performers! Is ‘doughnut’ a famous event or something? Or maybe a famous show? Anyways, I don’t know why but not only is it showing me Middle Eastern people, this time they are ALL on stage! Dancing, singing or posing!

(1 try) MindsEye: 🚫️ I guess than is a Middle Eastern man with a mustache and half a head scarf, but I can’t tell if it’s a bit of naan bread or a dog on the right...
Then i did a translation on Google Translate to add ‘a picture of’, so the second prompt is:
صورة دونات

(1 try) DALL-E mini: 🚫️ For some reason it printed only Middle Eastern-looking women, with two wearing hijabs. I don’t know if ‘doughnut’ in Arabic also means something else, like a homonym. Maybe it means women too. Or performers? Singing women? But yet again, it printed the people associated to the language / culture!

(2 tries) MindsEye: 🚫️ The first try was way too pixelated, but both generated random environments that reminded me of images of Middle Eastern places I see online like if you googled Egypt, street or Morocco, street.
Arabic Summary: Similar to the Viet, Hindi and Thai tests, it sometimes picks up on the language of the prompts being Arabic and associate it often with actual humans who look South Asian / Middle Eastern or who wears cultural clothing like hijabs/headscarves, a lot of perfomers for some reason, or even random environments resembling to images found online of places in the Arab-speaking countries like Algeria, Morocco, Pakistan with abstract, Arabic-looking glyphs printed.
Summary of each language:
Latin-languages
French Summary: Great! So French works fairly ok! It doesn’t pick up on old, rarer terms like ‘victuailles’, but it got the majority of prompts.Viet Summary: Similar to the Hindi and Arabic tests, it sometimes picks up on the language of the prompts being Vietnamese and associate it often with actual Viet-looking humans or to the closest English term / popular Internet term (so ‘bóng bàn‘ = Bing Bong from Inside Out)
Non-Latin-languages
Hindi Summary: Similar to the Viet, Thai and Arabic tests, it sometimes picks up on the language of the prompts being Hindi and associate it often with actual humans who look Indian / South-Asian or who wears bindis, or even random environments with abstract, Hindi-looking glyphs printed.Thai Summary: Similar to the Viet, Arabic and Hindi tests, it sometimes picks up on the language of the prompts being Thai and associate it often with actual humans who look Asian or who wears clothing found in the culture such as the sarongs or other cultural references such as the image that reminded me of buddhist art / sculptures, and landscapes / environments with abstract, Thai-looking glyphs printed.
Arabic Summary: Similar to the Viet, Hindi and Thai tests, it sometimes picks up on the language of the prompts being Arabic and associate it often with actual humans who look South Asian / Arab or who wears cultural clothing like hijabs/headscarves, a lot of perfomers for some reason, or even random environments resembling to images found online of places in the Arab-speaking countries like Algeria, Morocco, Pakistan with abstract, Arabic-looking glyphs printed.
Summary
Overall, it seems that latin-languages prompts are picked up slightly better, either some words are recognised as transparent words, or are popular enough that they can generate a fairly close result, or have been remapped based on the closest English-sounding word, whereas non-latin languages prompts often generate results based on the people / traditions / famous photos found on the Internet representing an almost stereotyped / touristy versions of the cultures where the language is spoken at the most, they all have abstracted version of their glyphs printed on the images too. I’m assuming that the generators have picked up on the glyphs themselves but not the meaning of the words.I would say that DALL-E mini worked better than MindsEye Beta, although read below in terms of finetuning as I might have misused the tool and not pushed it to its full potential.
Thoughts:
BIAS
I had to confront a lot of my own inner biases, when the Vietnamese hot chocolate result came out, as a Viet woman I immedietaly jumped to the conclusion that it was a sexual stereotype, and only later did I realise I wrote the words ‘hot’ and ‘cream’ in Viet.
Another bias I was worried about was that everytime it returned a result that was incorrect, I automatically ran the prompt a second or even third time, as I was worried I was falling into confirmation bias when attempting to generate results, including being super tempted to play around with the settings like the steps ect to get more accurate results. So I realised that for fairness I had to declare the amount of ‘tries’ I actually did and didn’t actually change the settings and kept the same for all the tests.
Also when it came to guessing the results for the languages I didn’t speak (Hindi, Arabic and Thai), the visual results made me guess based on my own biases what they were, so I assumed the people with bindis were Indian and that the images in the Thai Malajai example were landscapes in Thailand!
PROMPTS
I need to do refine my prompts. And log them methodically too. As I stated in my other article, my prompts could also just be terrible or too simple and might require more descriptive details within that language to produce the expected results.
TECHNICAL FEATURES (steps, generation model ect)
On MindsEye I used the exact same settings, which was the default setting: CLIP Guided Diffusion, using Disco Diffusion v5, 250 steps) and I wondered if a lot of the results from this generator could have been improved if I actually played around with the settings more, and perhaps fine-tuned those. There is a huge chance that a lot of the outcomes are due to user error, where I did not adapt the settings properly to get the result I wanted. I don’t know enough about the tools to know if this is the case, but it is definetely on my mind.
LANGUAGE LIMITATIONS
I noticed that I did more experiments in the French category simply because I am a native speaker. I was struggling to find words in Hindi, Arabic and Thai because I wasn’t sure what was correct on Google Translate.
I also want to expand to other languages, either closer in proximity to English such as German, Asian languages like Malay, Tagalog, Japanese, Korean or Cantonese / Mandarin or African languages like Yoruba or Bantu languages such as Zulu, or Eastern European ones like Lithuanian, Slovekian, Romanian, Russian, Ukrainian or Polish! Unfortunately my knowledge of languages is limited so would love to have people help me in this regard, both in choosing 3 languages without very little roots in common and people who actually speak the language!
FINAL THOUGHTS
This feels like i’m trying out Harry Potter spells lol.
I need to try this experiment again, this time by:
- Finetuning my prompts
- Find native speakers to help me find prompts
- Playing around with all the technical features on MindsEye
- Perhaps add a third AI-image generator platform in the mix
- Experiment by mixing English + other language prompts, e.g “un petit garçon, professional photography”