What the hell is latent space in machine learning?

Image from my Instagram post
Disclaimer: I am not an expert on any of the topics I shall discuss below, I am just curious and I like to experiment + learn. I’m using this platform to log my thoughts, ideas and whatever else comes to mind. Please take what I write with a pinch of salt, and always do your own research. I am not a very good writer either, so be prepared to be reading a lot of fluff.
Anything I write that might be wrong, please do correct me but be polite about it, thank you!
Date: Thursday 09/06/22
So now that DALL-E mini has exploded on the internet and Vox released a great video on AI-generated images, it’s time to look into some definitions. One of the things Vox described was the latent space in ML. I heard about it, I even know someone who named a whole art project out of it. But I realised that I never actually understood what it was.
So I went on Instagram and made a story where I had hundreds of people, including a bunch of users in the world of ML / DL / AI who saw but didnt respond. I assumed they were too busy to respond to a stupid story, but I was frustrated as I expected at least one person to reply.

screenshot of my instagram story
Eventually, two of my friends, Jehanne Hassan who is doing a PhD in Sciences (I can’t recall the exact degree, so sorry Jehanne) and David who just graduated from BA Fine Art Computing and who experimented with AI-generated images finally responded to me!
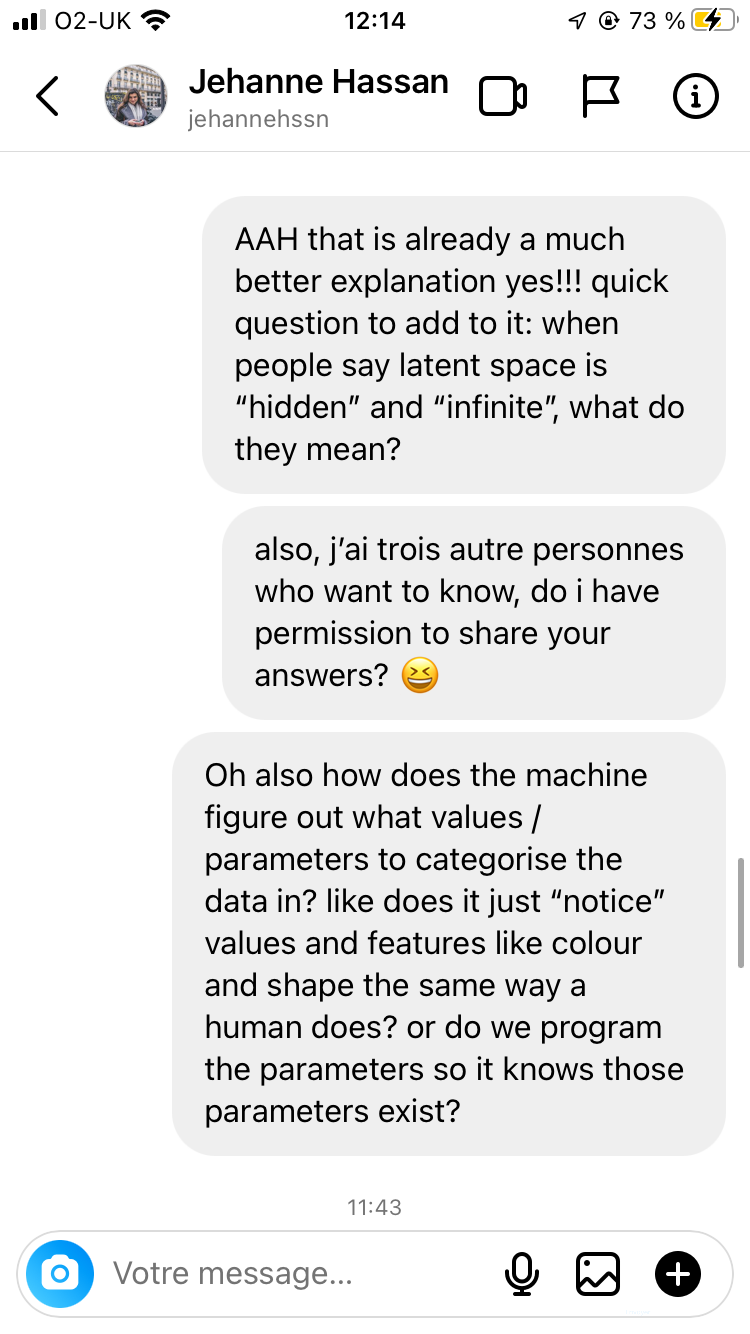
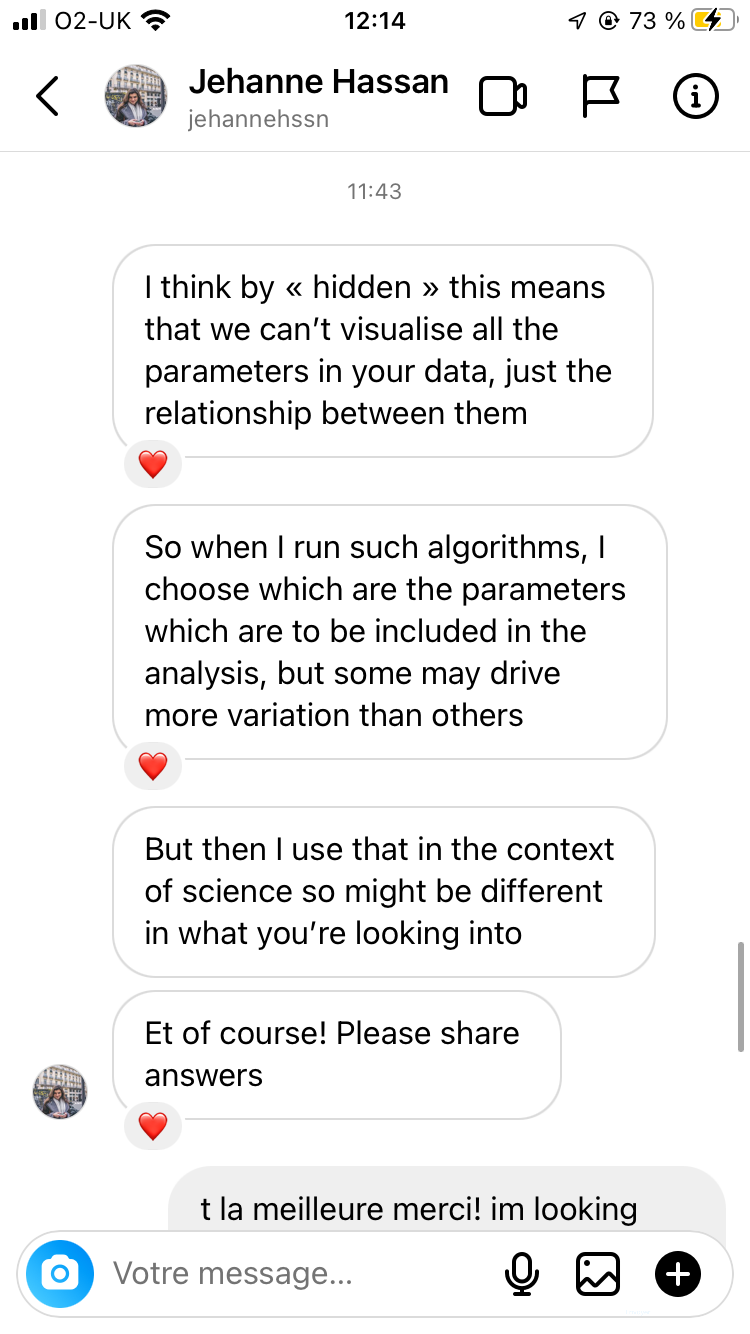
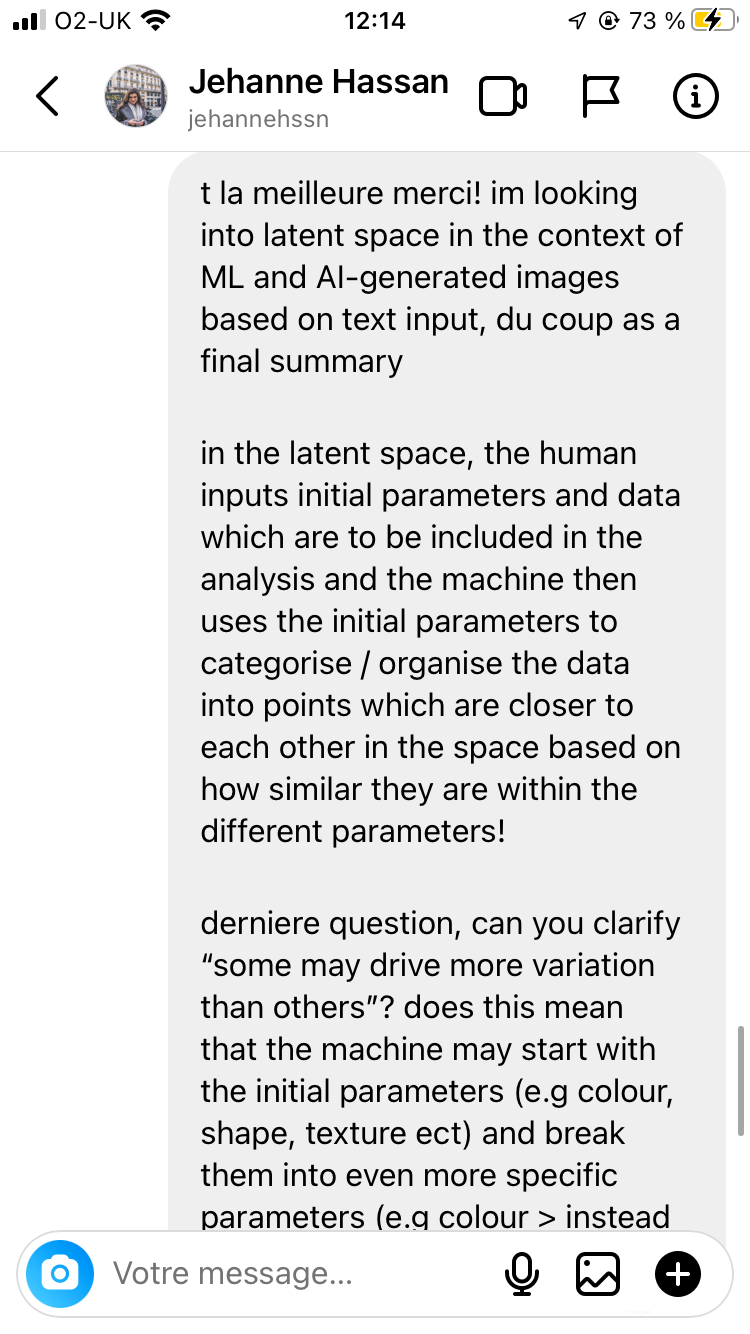
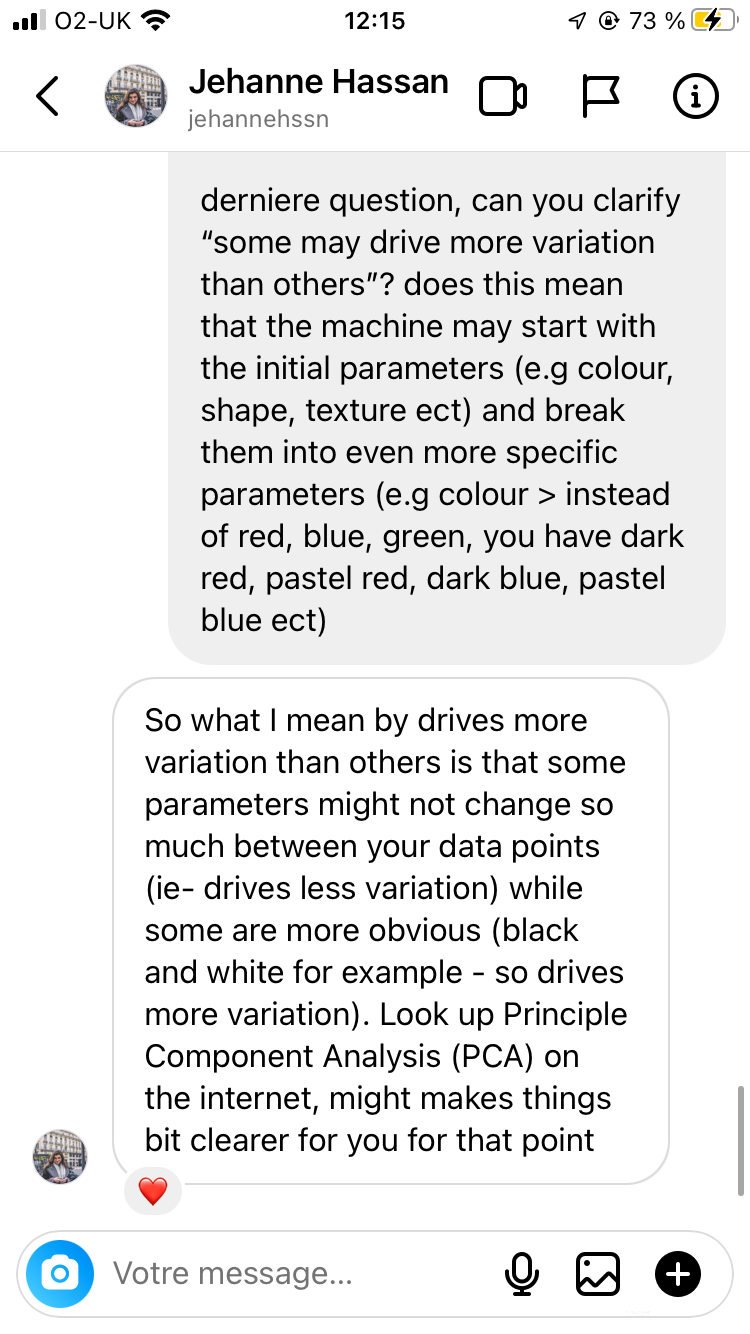
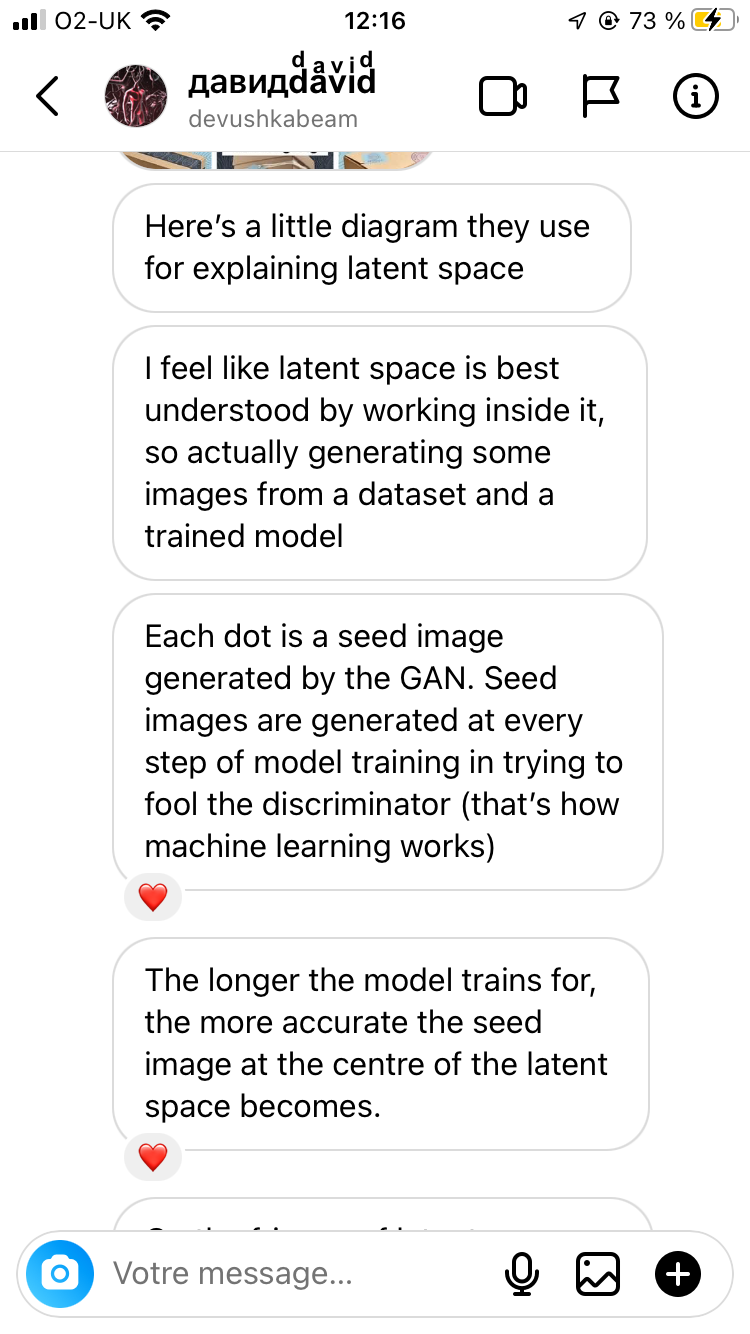

Swipe to view the responses from Jehanne and David
And this is my interpretation of what latent space is in AI-generated images based on their great responses and my own research including the Vox video:
So if i understood properly in crude terms (dont judge thats how i learn things): the latent space is an abstract multidimensional space where the machine is given large sets of data which it then compresses + organises into points, which are positioned closer or further apart from each other depending on how similar they are based on a set of parameters & values
So in that Vox video about AI generated images, its like if i chucked a 🍌 and a 🪑and a 🦞 to a machine and was like “give me an image with all three, make it make sense” and it would make sense of it by categorising those objects based on features like colour, texture & lighting, all of which is happening in that multidimensional space. And as it is categorising all them objects, it generates points of data called “seeds” which are initial visualisations of said data points, which in turn are “critiqued” by the discriminator at every step of the machine being trained, & the longer it trains, the clearer & more accurate the image of my 🦞🪑🍌 becomes
Did i get this right? i still have so many questions, although i am guilty of anthropomorphising a machine in my attempt to break this down in simple terms, that is the only way i can learn, by imagining the machine as a actual sentient object, but i am aware that it can be a slippery slope given the discussions on accountability in AI + ethics